- 定义变量
- 常量
- 字符串
- u64、i64、f64
- if
- match
- 读取文件
- 解析 json
- 循环
- iter
- while
- loop
- 函数
- 元组 tuple
- 结构体
- 枚举
- 集合
- 泛型
- Trait
- 迭代器
- 闭包
- 闭包的使用
- 线程
- 错误处理
- 智能指针
- Rc
基于引用计数的智能指针 - RefCell
: 使用了内部可变性模式的类型 - RefCell 和 Box 的区别
- 包管理
- 单元测试
- 集成测试
- bench
- Arc
- Mutex
- RwLock
- 时间格式
- 策略模式
- 多线程与定时任务
- channel
- rayon
- <'_> 是什么意思,什么作用
- 生命周期
- 函数指针
- 闭包与Fn、FnMut、FnOnce
- 宏
- 实现 kafka 的工具包,发布到 crate.io
定义变量
let 变量名 = 值; // 不指定变量类型
let 变量名:数据类型 = 值; // 指定变量类型
可以包含 字母、数字 和 下划线 。
变量名必须以 字母 或 下划线 开头。不能以 数字 开头。
变量名是 区分大小 写的。也就是大写的 Study 和小写的 study 是两个不同的变量。
let 关键字定义的变量是不可变变量
mut 表示可变,在变量前边加
常量
const 常量名称:数据类型=值;
Rust 中,常量不能被隐藏,也不能被重复定义。
字符串
Rust 语言提供了两种字符串
- Rust 核心内置的数据类型&str,字符串字面量 。
- Rust 标准库中的一个 公开 pub 结构体。字符串对象 String。
String::new() //创建一个新的空字符串,它是静态方法。
String::from() //从具体的字符串字面量创建字符串对象。
let mut s3 = String::new();
s3.push('O');
s3.push('K');
println!("{}",s3);//输出 Go语言极简一本通OK
replace()
len()
to_string()
as_str()
trim()
split()
chars()
u64、i64、f64
u64 是一个无符号的 64 位整数,表示范围为从 0 到 18,446,744,073,709,551,615,可用于表示不需要小数的正整数值。
i64 是一个带符号的 64 位整数,表示范围为 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807,可以表示正数和负数,适用于需要保存有符号整数的场景。
f64 是一个 64 位浮点数,可以表示带小数点的浮点值,并且可以表示非常小或非常大的数字,可以在一定的精度范围内表示几乎所有实数。但是由于精度限制,浮点数在进行数值计算时容易出现误差,所以需要谨慎使用。
在 Rust 中,您需要根据实际的应用场景选择合适的数据类型。如果您需要保存的整数是正数且不需要超过 u64 的取值范围,那么使用 u64 可能会更合适,而如果您需要保存的整数可以是正数或者负数,使用 i64 可能更合适。如果您需要进行小数数值计算,不需要非常高的精度,那么选择 f64 可能更简单。但是如果您需要进行高精度货币计算等精确计算,建议使用 Decimal 等第三方库。
需要注意的是,在 Rust 中,这三种类型之间的转换需要谨慎,因为它们的类型不兼容,并且在进行转换时,可能发生数据精度丢失等问题。对于 i64 到 f64 或者 u64 到 f64 的转换,可以使用 as 运算符。而对于 f64 到 i64 或者 f64 到 u64 的转换,需要使用 .round() 等函数将浮点数向上或向下取整,并处理溢出的情况。
if
if 条件表达式1 {
// 当 条件表达式1 为 true 时要执行的语句
} else if 条件表达式2 {
// 当 条件表达式2 为 true 时要执行的语句
} else {
// 如果 条件表达式1 和 条件表达式2 都为 false 时要执行的语句
}
let total:f32=366.00;
if total>200.00 && total<500.00{
println!("打9折,{}",total*0.9)
}else if total>500.00{
println!("打8折,{}",total*0.9)
} else{
println!("无折扣优惠,{}",total)
}
//输出 打9折,329.4
match
match variable_expression {
constant_expr1 => {
// 语句;
},
constant_expr2 => {
// 语句;
},
_ => {
// 默认
// 其它语句
}
};
let code = "10010";
let choose = match code {
"10010" => "联通",
"10086" => "移动",
_ => "Unknown"
};
println!("选择 {}", choose);
//输出 选择 联通
let code = "80010";
let choose = match code {
"10010" => "联通",
"10086" => "移动",
_ => "Unknown"
};
println!("选择 {}", choose);
//输出 选择 Unknown
读取文件
let content = fs::read_to_string("json.json").unwrap();
解析 json
let json = serde_json::to_string(&content).unwrap();
print!("json: {}", json);
let parsed:WebResponse = serde_json::from_str(raw_json).unwrap();
return pased
循环
for num in 1..5{
println!("num is {}", num);
}
//输出
num is 1
num is 2
num is 3
num is 4
for num in 1..=5 {
println!("num is {}", num);
}
输出
num is 1
num is 2
num is 3
num is 4
num is 5
iter
let array = vec![
"1",
"2",
"3",
];
for name in array.iter() {
match name {
&"3" => println!("3-{}!", name),
_ => println!("{}", name),
}
}
//输出
1
2
3-3!
iter 在每次迭代的时候会从集合中借用元素,这样集合本身不会被改变,循环结束后,集合依然可以使用。
into_iter会消耗集合,会remove 集合中的元素。
let array = vec![
"1",
"2",
"3",
];
for name in array.into_iter() { // `array` moved due to this method call
match name {
"3" => println!("3-{}!", name),
_ => println!("{}", name),
}
}
println!("{:?}",array) // value borrowed here after move
while
while ( 条件表达式 ) {
// 执行业务逻辑
}
let mut num = 1;
while num < 20 {
num = num + 1;
println!("{}",num)
}
while 内部也是可以使用 break;
loop
let mut num = 1;
loop {
num = num + 1;
if num > 20{
break;
}
println!("{}",num)
}
函数
fn 函数名称([参数:数据类型]) -> 返回值 {
// 函数代码
}
fn hello(){
println!("Hello, rust!");
}
fn main() {
hello();
}
//输出 Hello, rust!
一个 “不” 返回值的函数。实际上会返回一个单元类型 ()
函数返回值 ->
如果函数最后没有 return,那么函数会使用最后一条语句的执行结果当做返回值返回,没有分号。
参数-值传递
值传递 是把传递的变量的值传递给函数的 形参,所以,函数体外的变量值和函数参数是各自保存了相同的值,互不影响。因此函数内部修改函数参数的值并不会影响外部变量的值。
值传递变量导致重新创建一个变量
fn double_price(mut price:i32){
price=price*2;
println!("内部的price是{}",price)
}
fn main() {
let mut price=99;
double_price(price); //输出 内部的price是198
println!("外部的price是{}",price); //输出 外部的price是99
}
参数-引用传递
引用传递把当前变量的内存位置传递给函数。传递的变量和函数参数都共同指向了同一个内存位置。引用传递在参数类型的前面加上 & 符号。
fn 函数名称(参数: &数据类型) {
// 执行逻辑代码
}
fn double_price2(price:&mut i32){
*price=*price*2;
println!("内部的price是{}",price)
}
fn main() {
let mut price=88;
double_price2(&mut price); //输出 内部的price是176
println!("外部的price是{}",price);//输出 外部的price是176
}
元组 tuple
Tuple 元组是一个 复合类型 ,可以存储多个不同类型的数据。 Rust 支持元组 tuple 类型。元组使用括号 () 来构造(construct)。函数可以使用元组来返回多个值,因为元组可以拥有任意多个值。
元组一旦定义,就不能再增长或缩小,长度是固定的。元组的下标从 0 开始。
定义
let tuple变量名称:(数据类型1,数据类型2,...) = (数据1,数据2,...);
let tuple变量名称 = (数据1,数据2,...);
tuple 使用一对小括号 () 把所有元素放在一起,元素之间使用逗号 , 分隔。如果显式指定了元组的数据类型,那么数据类型的个数必须和元组的个数相同,否则会报错。
fn main() {
let t:(&str,&str) = ("GO","rust");
println!("{:?}",t);
println!("{}",t.0);
println!("{}",t.1);
// 解构,将2个元素的元组,赋值给两个变量
let (go,rust) = t;
println!("{}",go);
println!("{}",rust)
}
结构体
定义结构体
struct 结构体名称 {
字段1:数据类型,
字段2:数据类型,
...
}
创建结构体实例
let 实例名称 = 结构体名称{
field1:value1,
field2:value2
...
};
-------
#[derive(Debug)]
struct Study {
name: String,
target: String,
spend: i32,
}
fn main() {
let s = Study {
name: String::from("GO"),
target: String::from("GOGOGO"),
spend: 3,
};
println!("{:?}", s);
println!("{:?}", s.name);
}
结构体作为函数参数
fn show(s: Study) {
println!(
"name is :{} target is {} spend is{}",
s.name, s.target, s.spend
);
}
结构体作为返回值
fn get_instance(name: String, target: String, spend: i32) -> Study {
return Study {
name,
target,
spend,
};
}
方法
方法是依附于对象的函数。
这些方法通过关键字 self 来访问对象中的数据和其他。方法在 impl 代码块中定义。
与函数的区别
函数:可以直接调用,同一个程序不能出现 2 个相同的函数签名的函数,应为函数不归属任何 owner。
方法:归属某一个 owner,不同的 owner 可以有相同的方法签名。
impl 结构体{
fn 方法名(&self,参数列表) 返回值 {
//方法体
}
}
struct User{
name:String,
age:u32
}
impl User{
fn get_name(&self) -> String {
return String::from(self.name.to_string())
}
}
fn main() {
let user = User{
name:"zhangsan".to_string(),
age:1
};
println!("{}",user.get_name());
}
结构体静态方法
fn 方法名(参数: 数据类型,...) -> 返回值类型 {
// 方法体
}
调用方式
结构体名称::方法名(参数列表)
impl Study {
fn get_instance_another(name: String, target: String, spend: i32) -> Study {
return Study {
name,
target,
spend,
};
}
}
fn main() {
let s = Study::get_instance_another("GO".to_string(),"GOGOGO".to_string(),3);
println!("{:?}", s);
println!("{:?}", s.name);
}
枚举
enum 枚举名称{
variant1,
variant2,
...
}
使用:
枚举名称::variant
Option枚举
enum Option<T> {
Some(T), // 用于返回一个值
None // 用于返回 null,用None来代替。
}
Option 枚举经常用在函数中的返回值,它可以表示有返回值,也可以用于表示没有返回值。如果有返回值。可以使用返回 Some(data),如果函数没有返回值,可以返回 None。
集合
Rust 语言标准库提供了通用的数据结构的实现。包括 向量 (Vector)、哈希表( HashMap )、哈希集合( HashSet ) 。
Vec
Rust 在标准库中定义了结构体 Vec 用于表示一个向量。向量和数组很相似,只是数组长度是编译时就确定了,定义后就不能改变了,那要么改数组,让他支持可变长度,显然 Rust 没有这么做,它用向量这个数据结构,也是在内存中开辟一段连续的内存空间来存储元素。
特点:
- 向量中的元素都是相同类型元素的集合。
- 长度可变,运行时可以增加和减少。
- 使用索引查找元素。(索引从 0 开始)
- 添加元素时,添加到向量尾部。
- 向量的内存在堆上,长度可动态变化。
let mut 向量的变量名称 = Vec::new();
// 使用 vec宏简化
let 向量的变量名称 = vec![val1,val2,...]
常用方法
- new():创建一个空的向量实例
- push():添加到向量末尾
- remove():删除并返回指定的下表元素
- contains():判断向量中是否包含某个值
- len():返回向量中元素个数
vec 如何遍历
在 Rust 中,可以使用迭代器(iterator)来遍历 Vec 类型的向量。迭代器提供了一种简洁和安全的方式来遍历集合元素。
有多种方法可以遍历 Vec 的元素。下面是几个常用的示例:
- 使用
for循环:
let vec = vec![1, 2, 3, 4, 5];
for element in &vec {
println!("{}", element);
}
在上面的示例中,我们使用 for 循环遍历了 vec 中的每个元素,并打印出来。
- 使用
iter()方法和for循环:
let vec = vec![1, 2, 3, 4, 5];
for element in vec.iter() {
println!("{}", element);
}
这里我们调用 iter() 方法获取一个迭代器,然后使用 for 循环遍历迭代器中的每个元素。
- 使用
iter_mut()方法和for循环(可变迭代):
let mut vec = vec![1, 2, 3, 4, 5];
for element in vec.iter_mut() {
*element *= 2; // 修改元素的值
}
println!("{:?}", vec); // 打印修改后的向量
在这个示例中,我们使用 iter_mut() 方法获取一个可变迭代器,然后使用 for 循环遍历可变迭代器中的每个元素。我们在循环体内修改了每个元素的值,并打印出修改后的向量。
let vec = vec![10, 20, 30, 40, 50];
for (index, element) in vec.iter().enumerate() {
println!("Index: {}, Element: {}", index, element);
}
这些示例展示了几种常用的遍历 Vec 的方法。你可以根据具体的需求选择适合的方法来遍历和操作 Vec 中的元素。
HashMap
let mut 变量名称 = HashMap::new();
fn main() {
let mut map = HashMap::new();
map.insert(1,"rust");
map.insert(2,"go");
map.insert(3,"java");
println!("len = {}",map.len());
let value = map.get(&1);
match value {
Some(v) =>{
println!("{}",v)
}
None =>{
println!("none")
}
}
let map2 = map.clone();
for x in map2 {
println!("{:?}",x)
}
for (k,v) in map.iter() {
println!("k = {},v = {}",k,v);
}
}
HashSet
Hashset 是相同数据类型的集合,它是没有重复值的。如果集合中已经存在相同的值,则会插入失败。
let mut 变量名称 = HashSet::new();
BTreeMap、LinkedHashMap
HashMap 是一个哈希映射,它使用哈希函数对键进行索引,因此它不会按照插入顺序保存元素。
泛型
Rust 语言中的泛型主要包含 泛型集合、泛型结构体、泛型函数、范型枚举 和 特质 。
Rust 使用使用
struct 结构体名称<T> {
元素:T,
}
struct Data<T> {
value:T,
}
fn main() {
let t:Data<i32> = Data{value:100};
println!("值:{} ",t.value);//输出 值:100
let t:Data<f64> = Data{value:66.00};
println!("值:{} ",t.value);//输出 值:66
let t:Data<String> = Data{value:"123".to_string()};
println!("值:{} ",t.value);//输出 值 123
}
Trait
可以把这个特质(traits)对标其他语言的接口,都是对行为的抽象。使用 trait关键字用来定义。特质,可以包含具体的方法,也可以包含抽象的方法。
trait some_trait {
// 没有任何实现的虚方法
fn method1(&self);
// 有具体实现的普通方法
fn method2(&self){
//方法的具体代码
}
}
实现特质 demo
struct Book {
name: String,
id: u32,
author: String,
}
trait ShowBook {
fn Show(&self);
}
impl ShowBook for Book{
fn Show(&self) {
println!("Id:{},Name:{},Author:{}",self.id,self.name,self.author);
}
}
fn main() {
let book = Book{
id:1,
name: String::from("GO"),
author: String::from("xx")
};
book.Show();
}
泛型函数
fn 方法名<T[:特质名称]>(参数1:T, ...) {
// 函数实现代码
}
fn show2<T:Display>(t:T){
println!("{}",t);
}
impl Display for Book{
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
println!("Id:{},Name:{},Author:{}",self.id,self.name,self.author);
let r=Result::Ok(());
return r;
}
}
show2(book);
迭代器
迭代器 就是把集合中的所有元素按照顺序一个接一个的传递给处理逻辑。
Iterator 特质有两个函数:
- 一个是 iter(),用于返回一个 迭代器 对象,也称之为 项 ( items ) 。
- 一个是 next(),用于返回迭代器中的下一个元素。如果已经迭代到集合的末尾(最后一个项后面)则返回 None。
fn main() {
let array = vec![
"1",
"2",
"3",
];
let mut iter = array.iter();
println!("{:?}",iter.next());
println!("{:?}",iter.next());
println!("{:?}",iter.next());
for x in array {
println!("{:?}",x)
}
}
闭包
Rust 中的闭包(closure),也叫做 lambda 表达式或者 lambda,是一类能够捕获周围作用域中变量的函数。
调用一个闭包和调用一个函数完全相同,不过调用闭包时,输入和返回类型两者都可以自动推导,而输入变量名必须指明。
其他的特点包括:
- 声明时使用 || 替代 () 将输入参数括起来。
- 函数体定界符({})对于单个表达式是可选的,其他情况必须加上。
- 有能力捕获外部环境的变量。
普通函数
fn 函数名(参数列表) -> 返回值 {
// 业务逻辑
}
// 闭包
|参数列表| {
// 业务逻辑
}
// 无参数闭包
|| {
// 业务逻辑
}
let 闭包变量 = |参数列表| {
// 闭包的具体逻辑
}
fn main() {
let double = |x| { x * 2 };
let add = |a, b| { a + b };
let x = add(2, 4);
println!("{:?}", x);
let y = double(5);
println!("{:?}", y);
let v = 3;
let add2 = |x| { v + x };
println!("{:?}", add2(4));
let r = (|x| x + 1)(3); // 3 是参数,结果r是4
}
闭包就是在一个函数内创建立即调用的另一个函数。
闭包是一个匿名函数。
闭包虽然没有函数名,但可以把整个闭包赋值一个变量,通过调用该变量来完成闭包的调用。
闭包不用声明返回值,但它却可以有返回值。并且使用最后一条语句的执行结果作为返回值。闭包的返回值可以赋值给变量。
闭包又称之为 内联函数。可以让闭包访问外层函数里的变量。
闭包的使用
https://www.go-edu.cn/2022/07/05/rust-39-%E9%97%AD%E5%8C%85%E7%9A%84%E4%BD%BF%E7%94%A8/
let add = |x, y| x + y;
let result = add(3, 4);
println!("{}", result);
------------
闭包像普通函数一样被调用。
fn receives_closure<F>(closure: F)
where
F: Fn(i32, i32) -> i32,
{
let result = closure(3, 5);
println!("闭包作为参数执行结果 => {}", result);
}
fn main() {
let add = |x, y| x + y;
receives_closure(add);
}
输出:
闭包作为参数执行结果 => 8
------------
闭包捕获变量
fn receives_closure2<F>(closure:F)
where
F:Fn(i32)->i32{
let result = closure(1);
println!("closure(1) => {}", result);
}
fn main() {
let y = 2;
receives_closure2(|x| x + y);
let y = 3;
receives_closure2(|x| x + y);
}
输出:
捕获变量的结果 => 3
捕获变量的结果 => 4
-------
返回闭包
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 6
}
fn main() {
let closure = returns_closure();
println!("返回闭包 => {}", closure(1));
}
输出:
返回闭包 => 7
------
参数和返回值都有闭包
线程
创建线程
std::thread::spawn()
//spawn() 函数的原型
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
fn main() {
//子线程
thread::spawn(|| {
for i in 1..10 {
println!("子线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
});
// 主线程
for i in 1..5 {
println!("主线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
}
|| 是闭包,匿名函数,也可以使用外部函数
fn a(){
for i in 1..10 {
println!("子线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
}
fn main() {
thread::spawn(a);
// 主线程
for i in 1..5 {
println!("主线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
}
join
上面的例子主线程结束后,子线程还没有运行完,但是子线程也结束了。如果想让子线程结束后,主线程再结束,我们就要使用Join 方法,把子线程加入主线程等待队列。
fn a(){
for i in 1..10 {
println!("子线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
}
fn main() {
let handler = thread::spawn(a);
// 主线程
for i in 1..5 {
println!("主线程 {}", i);
thread::sleep(Duration::from_millis(1));
}
handler.join().unwrap();
}
错误处理
panic!() 不可恢复错误
panic!() 程序立即退出,退出时调用者抛出退出原因。
fn main() {
panic!("出错啦");
println!("Hello Rust"); // 不可能执行的语句
}
//输出
thread 'main' panicked at '出错啦', src/main.rs:2:5
Result 枚举和可恢复错误
枚举的定义
enum Result<T,E> {
OK(T),
Err(E)
}
OK(T) T OK 时作为正常返回的值的数据类型。
Err(E) E Err 时作为错误返回的错误的类型。
unwrap() 和 expect()
unwrap是 Result<T, E>的方法,在实例上调用此方法时,如果是 Ok 枚举值,就会返回 Ok 中的对象,如果是 Err 枚举值,在运行时会 panic,报错信息是 format!(“{}”, error)。其缺点是,如果在不同地方都使用 unwrap,运行时出现 panic 的时候。
fn is_even(no:i32)->Result<bool,String> {
return if no % 2 == 0 {
Ok(true)
} else {
Err("输入值,不是偶数".to_string())
}
}
let result = is_even(6).unwrap();
println!("结果 {}",result);
//输出 结果 true
let result = is_even(11).unwrap();
println!("结果 {}",result);
//输出 thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: "输入值,不是偶数"'
expect方法的作用和unwrap类似,区别在于,expect方法接受msg: &str作为参数,它在运行时的panic信息为format!("{}: {}", msg, error),使用expect时,可以自定义报错信息,因此出现panic时比较容易定位。
let f = File::open("abc.txt").expect("无法打开该文件"); // 文件不存在
//输出 thread 'main' panicked at '无法打开该文件: Os { code: 2, kind: NotFound, message: "No such file or directory" }'
智能指针
指针,指代那些包含内存地址的变量。这个地址被用于索引,或者说用于指向内存中的其他数据。
rust 中最常用的指针就是 引用。
而智能指针则是一些数据结构,他们的行为类似于指针但拥有额外的元数据和附加功能。
引用是只借用数据的指针,而大多数智能指针本身就拥有它们指向的数据。
String 和 Vec<T> 也是智能指针。因为他们拥有一片内存区域并允许用户对其进行操作。他们还拥有元数据,例如容量,并提供额外的功能或保障。
一般用结构体实现智能指针,通常会实现 Deref 和 Drop 这两个 trait。
Deref 使得智能指针结构体的实例拥有与引用一致的行为,可以编写出能够同时用于引用和智能指针的代码
Drop 可以自定义智能指针离开作用域时运行的代码。
常见的智能指针:
Box<T>:可用于在堆上分配值。Rc<T>:允许多重所有权的引用计数类型。Ref<T>和RefMut<T>:可以通过RefCell<T>访问,是一种可以在运行时而不是编译时执行借用规则的类型。
内部可变性模式,使用了这一模式的不可变类型会暴露出能够改变自己内部值的 API。
使用 Box 在堆上分配数据
Box<T> 装箱,是最简单直接的一种智能指针。将数据保存在堆上,并在栈中保留一个指向堆数据的指针。
装箱使用场景:
- 当拥有一个无法编译时确定大小的类型,但又想在一个要求固定尺寸的上下文环境中使用这个类型的值时
- 当希望拥有一个实现了指定 trait 的类型值,但又不关心具体的类型时
通过 Deref trait 将智能指针视作常规引用
实现这个 trait 可以自定义解引用运算符的行为
use std::ops::Deref;
/// 定义一个 名为 MyBox 的结构体。结构体的定义中附带了泛型参数 T,可以存储任意类型的值。
/// MyBox 是一个拥有 T 类型单元素的元组结构体。
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
impl<T> Deref for MyBox<T> {
// 定义了 Deref trait 的一个关联类型、
// 关联类型是一种稍微有些不同的泛型参数定义方式。
type Target = T;
// 返回一个指向值的引用。进而允许通过 * 访问。
// * -> *(y.deref())
fn deref(&self) -> &Self::Target {
&self.0
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
Rust 语言把指针封装在如下两个特质Trait中。
Deref std::ops::Deref 用于创建一个只读智能指针,例如 *v
Drop std::ops::Drop 智能指针超出它的作用域范围时会回调该特质的 drop() 方法。 类似于其它语言的 析构函数。
当一个结构体实现了以上的接口后,它们就是智能指针。
Rust 提供了在 堆 上存储数据的能力并把这个能力封装到了 Box 中。
这种把 栈 上数据搬到 堆 上的能力,我们称之为 装箱。
Box 指针可以把数据存储在堆(heap)上,而不是栈(stack)上。这就是装箱(box),栈(stack)还是包含指向 堆(heap) 上数据的指针。
fn main() {
let a = 6; // 默认保存在 栈 上
let b = Box::new(a); // 使用 Box 后数据会存储在堆上
println!("b = {}", b);// 输出 b = 6
}
Rc 基于引用计数的智能指针
某些场景下,单个值可能同时被多个所有者持有,Rust 提供了一个名为 Rc<T>的类型来支持多重所有权,RC 是 Reference counting (引用计数)的缩写。
Rc<T> 类型的实例会在内部维护一个用于记录值引用次数的计数器,从而确定这个值是否仍在使用。
将堆上的一些数据分享给程序的锁哥部分同时使用,而又无法在编译期确定哪个部分会最后释放这些数据时,就可以使用 Rc<T> 类型、Rc 仅适用于单线程场景。
clone Rc 会增加引用计数
RefCell: 使用了内部可变性模式的类型
RefCell 代表了其持有数据的唯一所有权。
内部可变性,是 Rust 的设计模式之一,它允许你在只持有不可变引用的前提下对数据进行修改;通常而言,类似的行为会被借用规则所禁止。
为了能够改变数据,内部可变性模式在它的数据结构中使用了 unsafe 代码来绕过 Rust 正常的可变性和借用规则。
RefCell 和 Box 的区别
借用规则:
- 在任何给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用
- 引用总是有效的。
Box 会遵循这个借用规则,在使用 RefCell 时,Rust 只会在运行时检查这些规则,并在出现违反借用规则的情况下 panic
包管理
https://blog.hitol.top/16727524082529.html
单元测试
#[test]
fn it_works(){
let result = 2 + 2;
assert_eq!(result,4);
}
集成测试
cargo 在与 src 同级别的 tests 目录寻找集成测试。
tests/xxx.rs
#[test]
fn it_works(){
let result = 2 + 2;
assert_eq!(result,4);
}
tests 目录中的每一个 Rust 源文件都被编译成一个单独的 crate。
bench
针对性能测试,能够返回该 test 执行的时间。ns 级别。
Arc
Arc(Atomic Reference Counted)是 Rust 标准库中的一种类型,它实现了原子引用计数(Atomic Reference Counting)。Arc 可以在多个线程间共享数据,而不必担心数据安全。
Arc 使用了一个内部计数器,来记录有多少个引用指向该数据。当最后一个引用被销毁时,Arc 会自动销毁数据。
例如:
use std::sync::Arc;
use std::thread;
fn main() {
let data = Arc::new(vec![1, 2, 3, 4, 5]);
for i in 0..5 {
let data = data.clone();
thread::spawn(move || {
println!("Thread {}: {:?}", i, data);
});
}
}
在上面的代码中,我们创建了一个用于存储整数的 vector,并用 Arc 包装它。然后在循环中,我们创建了五个线程,每个线程都有一个对该 vector 的引用。当最后一个引用被销毁时,Arc 会自动销毁 vector。
Arc 是一种非常有用的工具,特别是当你需要在多个线程间共享数据时,可以替代手写的计数器。
Mutex
RwLock
RwLock 是 Rust 标准库中的一种类型,用于实现读写锁。读写锁是一种线程同步机制,它可以同时允许多个读线程读取共享数据,但是只允许一个写线程对共享数据进行修改。
use std::sync::{Arc, RwLock};
use std::thread;
fn main() {
let data = Arc::new(RwLock::new(vec![1, 2, 3, 4, 5]));
for i in 0..5 {
let data = data.clone();
thread::spawn(move || {
let mut data = data.write().unwrap();
data[i] += 1;
});
}
thread::sleep_ms(50);
let data = data.read().unwrap();
println!("{:?}", data);
}
在上面的代码中,我们创建了一个用于存储整数的 vector,并用 RwLock 包装它。然后在循环中,我们创建了五个线程,每个线程都试图对该 vector 进行修改。由于我们使用了读写锁,因此在任意时刻只有一个线程能够修改 vector,从而避免了竞争条件的产生。
RwLock 是一种非常有用的工具,特别是当你需要保护共享数据不被多个线程同时修改时,可以使用它来保证数据安全。
时间格式
use chrono::{DateTime, Utc};
fn main() {
let now: DateTime<Utc> = Utc::now();
println!("UTC now is: {}", now);
println!("UTC now in RFC 2822 is: {}", now.to_rfc2822());
println!("UTC now in RFC 3339 is: {}", now.to_rfc3339());
println!("UTC now in a custom format is: {}", now.format("%a %b %e %T %Y"));
}
策略模式
在 Rust 中,策略模式是一种常见的设计模式,用于将算法与其实现分离开来,并在运行时动态选择不同的算法实现。
以下是一个简单的示例代码,展示了如何使用策略模式来实现对两个整数进行加法、减法和乘法计算:
trait Calculator {
fn calculate(&self, a: i32, b: i32) -> i32;
}
struct AddCalculator;
impl Calculator for AddCalculator {
fn calculate(&self, a: i32, b: i32) -> i32 {
a + b
}
}
struct SubtractCalculator;
impl Calculator for SubtractCalculator {
fn calculate(&self, a: i32, b: i32) -> i32 {
a - b
}
}
struct MultiplyCalculator;
impl Calculator for MultiplyCalculator {
fn calculate(&self, a: i32, b: i32) -> i32 {
a * b
}
}
struct Context<'a> {
calculator: Box<dyn Calculator + 'a>,
}
impl<'a> Context<'a> {
fn new(calculator: Box<dyn Calculator + 'a>) -> Self {
Self { calculator }
}
fn set_calculator(&mut self, calculator: Box<dyn Calculator + 'a>) {
self.calculator = calculator;
}
fn execute(&self, a: i32, b: i32) -> i32 {
self.calculator.calculate(a, b)
}
}
fn main() {
let mut context = Context::new(Box::new(AddCalculator));
println!("1 + 2 = {}", context.execute(1, 2));
context.set_calculator(Box::new(SubtractCalculator));
println!("3 - 1 = {}", context.execute(3, 1));
context.set_calculator(Box::new(MultiplyCalculator));
println!("2 * 4 = {}", context.execute(2, 4));
}
在上面的代码中,首先定义了一个 Calculator trait,该 trait 包含一个用于计算两个整数的 calculate() 方法。然后,分别实现了 AddCalculator、SubtractCalculator 和 MultiplyCalculator 三种不同的计算方法,并让它们都实现了 Calculator trait。
接着,定义了一个 Context 结构体,包含一个 Box
最后,在 main() 函数中,创建一个 Context 对象,并使用 execute() 方法分别执行加法、减法和乘法计算。
需要注意的是,采用策略模式可以解除算法与其实现之间的耦合关系,并提高代码的可扩展性和可维护性。同时,也可以根据具体需求选择不同的计算方法,从而灵活地应对各种计算场景。
#[derive(Clone, Copy)]
struct TaskRecord {
code: u32,
}
trait TaskStepService {
fn do_task_step(task_record: &TaskRecord);
fn retry_task_step(task_record: &TaskRecord);
}
pub struct StepA;
impl TaskStepService for StepA {
fn do_task_step(task_record: &TaskRecord) {
println!("Do task step A with code {}", task_record.code);
}
fn retry_task_step(task_record: &TaskRecord) {
println!("Retry task step A with code {}", task_record.code);
}
}
pub struct StepB;
impl TaskStepService for StepB {
fn do_task_step(task_record: &TaskRecord) {
println!("Do task step B with code {}", task_record.code);
}
fn retry_task_step(task_record: &TaskRecord) {
println!("Retry task step B with code {}", task_record.code);
}
}
enum TaskStep {
A(StepA),
B(StepB),
}
impl TaskStep {
fn from_code(code: u32) -> Option<Self> {
match code {
1 => Some(Self::A(StepA)),
2 => Some(Self::B(StepB)),
_ => None,
}
}
}
fn process_task_step(task_record: TaskRecord) {
if let Some(step) = TaskStep::from_code(task_record.code) {
match step {
TaskStep::A(service) => service.do_task_step(&task_record),
TaskStep::B(service) => service.do_task_step(&task_record),
}
} else {
println!("Invalid task code: {}", task_record.code);
}
}
fn retry_task_step(task_record: TaskRecord) {
if let Some(step) = TaskStep::from_code(task_record.code) {
match step {
TaskStep::A(service) => service.retry_task_step(&task_record),
TaskStep::B(service) => service.retry_task_step(&task_record),
}
} else {
println!("Invalid task code: {}", task_record.code);
}
}
pub fn main() {
let task_record1 = TaskRecord { code: 1 };
let task_record2 = TaskRecord { code: 2 };
let task_record3 = TaskRecord { code: 3 };
process_task_step(task_record1);
process_task_step(task_record2);
process_task_step(task_record3);
retry_task_step(task_record1);
retry_task_step(task_record2);
retry_task_step(task_record3);
}
报错还未解决
struct TaskRecord {
code: u32,
}
trait TaskStepService {
fn do_task_step(&self, task_record: &TaskRecord) {
println!("default do_task_step implementation for code {}", task_record.code);
}
fn retry_task_step(&self, task_record: &TaskRecord) {
println!("default retry_task_step implementation for code {}", task_record.code);
}
}
struct TaskStepServiceImpl1;
impl TaskStepService for TaskStepServiceImpl1 {
fn do_task_step(&self, task_record: &TaskRecord) {
println!("TaskStepServiceImpl1 do_task_step implementation for code {}", task_record.code);
}
fn retry_task_step(&self, task_record: &TaskRecord) {
println!("TaskStepServiceImpl1 retry_task_step implementation for code {}", task_record.code);
}
}
struct TaskStepServiceImpl2;
impl TaskStepService for TaskStepServiceImpl2 {
fn do_task_step(&self, task_record: &TaskRecord) {
println!("TaskStepServiceImpl2 do_task_step implementation for code {}", task_record.code);
}
fn retry_task_step(&self, task_record: &TaskRecord) {
println!("TaskStepServiceImpl2 retry_task_step implementation for code {}", task_record.code);
}
}
fn main() {
let task_record = TaskRecord { code: 1 };
match task_record.code {
1 => {
let service = TaskStepServiceImpl1 {};
service.do_task_step(&task_record);
service.retry_task_step(&task_record);
},
2 => {
let service = TaskStepServiceImpl2 {};
service.do_task_step(&task_record);
service.retry_task_step(&task_record);
},
_ => println!("unsupported code {}", task_record.code),
}
}
多线程与定时任务
use std::future::Future;
use std::pin::Pin;
use tokio::time::{sleep, Duration};
pub async fn do_task() -> Result<(), Box<dyn std::error::Error + Send + Sync>> {
loop {
println!("Running scheduled task...");
// 执行定时任务的代码...
println!("hello ");
sleep(Duration::from_secs(2)).await;
}
}
pub fn spawn_task() -> Pin<Box<dyn Future<Output = ()> + Send + Sync>> {
let fut = async move {
if let Err(err) = do_task().await {
eprintln!("Scheduled task failed: {:?}", err);
}
};
Box::pin(fut)
}
---
mod job;
use std::collections::HashMap;
use std::time::Duration;
use tokio::time::{interval, Instant, sleep};
#[actix_web::main]
async fn main() {
let task = job::do_task();
tokio::spawn(task);
sleep(Duration::from_secs(60)).await;
}
channel
use std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {}", received);
}
rayon
https://youtu.be/gof_OEv71Aw?t=1186

工作窃取是多线程计算机程序的一种调度策略。它解决了在具有固定数量处理器的静态多线程计算机上执行动态多线程计算的问题,该计算可以生成新的执行线程。在执行时间、内存使用和处理器间通讯方面都很有效。
在工作窃取调度器中,计算机每个处理器都有一个队列,当一个处理器队列空了的时候,它会查看其他处理器的队列并窃取工作到自己处理器上进行处理。
事实上,工作窃取即将工作分配到空闲的处理器上,只要所有处理器都有工作要做,就不会发生调度开销?
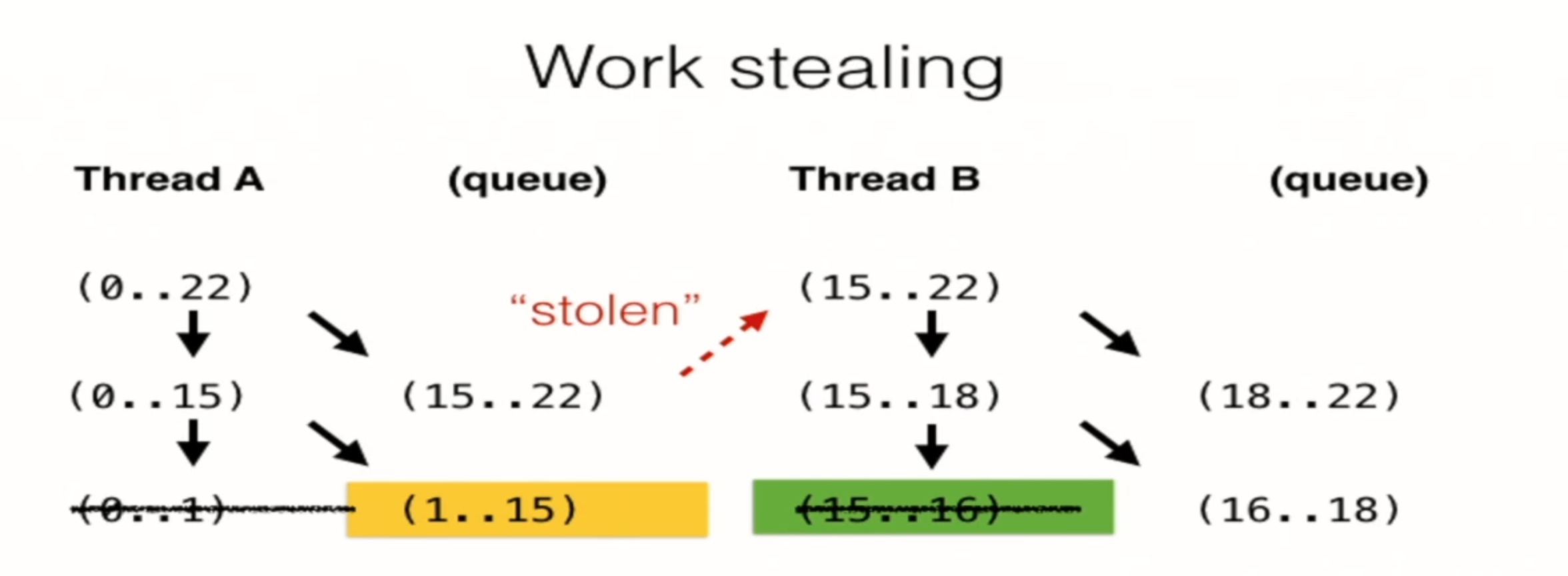
Rayon 的工作窃取算法是一种任务调度算法,用于在并行计算中动态地将任务分配给线程池中的线程。它的核心思想是线程可以从其他线程的任务队列中“窃取”任务来执行,以保持线程的高利用率。
以下是简单理解 Rayon 工作窃取算法的步骤:
-
初始化线程池:在启动时,Rayon 会创建一个线程池,其中包含多个工作线程。
-
任务分割:当有任务需要执行时,Rayon 将任务划分为更小的子任务,并将它们放入当前线程的任务队列中。
-
任务执行:每个工作线程从自己的任务队列中获取任务并执行。当线程完成自己的任务队列中的任务后,它会尝试从其他线程的任务队列中“窃取”任务。
-
工作窃取:当一个线程窃取任务时,它会选择一个空闲的线程,并从该线程的任务队列的末尾“窃取”一个任务。这样做的好处是可以避免线程空闲等待任务的情况,提高线程的利用率。
-
任务终止:当一个线程完成所有的任务后,它会检查其他线程的任务队列是否还有未完成的任务。如果存在未完成的任务,线程会继续尝试窃取任务,直到所有任务完成。
通过工作窃取算法,Rayon 可以自动将任务分配给线程池中的线程,并且在任务执行过程中动态地平衡负载,以提高并行计算的性能和效率。这种算法的优势在于它可以自动处理任务的分配和负载均衡,使得并行计算更加简单和高效。
<'_> 是什么意思,什么作用
在 Rust 中,<'_> 用于定义匿名生命周期。
生命周期是 Rust 中管理内存和引用的机制,它用于确保程序中的引用安全有效。通常,生命周期标记使用单引号 ' 来表示。例如:
fn foo<'a>(x: &'a i32) -> &'a i32 {
x
}
在这个例子中,<'a> 表示 foo() 函数使用一个生命周期 a,该生命周期确保返回值 &'a i32 的引用与参数 x: &'a i32 的生命周期相同。
<'_> 是一种特殊的生命周期标记,它表示一个匿名生命周期。这意味着,Rust 编译器会自动确定匿名生命周期的实际生命周期,无需手动指定。
例如,以下代码中的 <'_> 标记可以自动确定 s 和 s2 的实际生命周期,而无需指定具体的生命周期名称:
fn print_str(s: &str) {
println!("{}", s);
}
fn main() {
let s = String::from("Hello, world!");
let s2: &str = &s;
print_str(s2);
}
在这个例子中,我们定义了一个函数 print_str(),该函数接受一个字符串引用,并在控制台上打印出它。在 main() 函数中,我们首先定义了一个字符串 s,然后获取它的引用 s2,并将其传递给 print_str() 函数。 接下来我们将参数转换为 &str 类型。在这个过程中,我们使用了 <'_> 标记来表示一个匿名生命周期,此时 Rust 编译器会自动确定 s 和 s2 的实际生命周期,从而使得该代码更简洁,更易于阅读和维护。
总之, <'_> 适用于匿名生命周期,可以让代码更简洁,并且让 Rust 编译器自动确定实际生命周期。如果您不需要手动编写生命周期标记,并且可以让编译器自动确定生命周期,则可以使用 <'_> 来代替具体的生命周期名称。
生命周期
在Rust中,生命周期(lifetimes)是一种用于管理引用的机制,确保引用在其所引用的数据有效时才被使用。生命周期注解(lifetimes annotations)是Rust语言的一部分,用于明确指定引用的有效范围,以避免悬垂引用(dangling references)和使用已经被释放的数据的错误。
生命周期注解通常以撇号(')后跟一个标识符的形式表示,例如'a。这些标识符可以是任意名称,但通常使用单个字母来表示生命周期的名称。在函数签名、结构体定义和trait实现等地方,可以使用生命周期注解来指定引用的有效范围。
以下是一些常见的生命周期注解用法:
- 函数签名中的生命周期注解:
fn foo<'a>(x: &'a i32) -> &'a i32 {
// 函数体
x
}
在这个例子中,'a是一个生命周期注解,用于指定参数x和返回值之间的关系。它表示返回的引用的生命周期与参数x的生命周期相同。
- 结构体中的生命周期注解:
struct Foo<'a> {
x: &'a i32,
y: &'a i32,
}
impl<'a> Foo<'a> {
fn new(x: &'a i32, y: &'a i32) -> Foo<'a> {
Foo { x, y }
}
}
在这个例子中,'a是一个生命周期注解,用于指定结构体Foo中两个引用字段x和y的生命周期。
- Trait中的生命周期注解:
trait Bar<'a> {
fn baz(&'a self);
}
在这个例子中,'a是一个生命周期注解,用于指定实现Bar trait的类型中self引用的生命周期。
需要注意的是,生命周期注解并不会创建新的生命周期,而是用于指定引用之间的关系。它们帮助编译器在编译时进行静态检查,以确保引用的有效性。生命周期注解的具体使用方式取决于代码的上下文和需求。
一般来说,如果一个生命周期参数出现在另一个生命周期参数之前,那么前者的生命周期比后者更长。这种关系可以通过'a: 'b的语法来表示,其中'a是较长的生命周期,'b是较短的生命周期。
下面是一些示例来说明生命周期大小关系的表示方法:
fn foo<'a, 'b>(x: &'a i32, y: &'b i32) {
// ...
}
在这个例子中,'a和'b是两个生命周期参数。如果我们想表示'a比'b更长的关系,可以使用'a: 'b:
fn foo<'a, 'b>(x: &'a i32, y: &'b i32) {
// 'a: 'b 表示 'a 比 'b 更长
// ...
}
这表示x的生命周期'a比y的生命周期'b更长。换句话说,x的引用可以存在于y的引用之外。
'a:'b 表示 a 的生命周期 >= b 的生命周期。
函数指针
将普通函数传递至其他函数
函数在传递的过程中会被强制转换成 fn 类型,fn 就是函数指针。
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {}", answer);
}
fn 是一个类型而不是一个 trait。
函数指针实现了全部 3 中闭包 trait(Fn、FnMut、FnOnce),所以可以把函数指针
用作参数传递给一个接收闭包的函数。
倾向于使用搭配闭包 trait 的泛型来编写函数,这样的函数可以同时处理闭包与普通函数。
闭包与Fn、FnMut、FnOnce
fn main() {
let s = String::from("closure test");
let f1 = || println!("{}", s); // 不可变借用,这里 闭包就相当于 Fn
f1();
let mut s = String::from("closure test mut");
// 注意由于这里是使用可变借用,因此,闭包函数的接收者也必须声明为可变借用类型
let mut f2 = || {
s.push_str(", hello!");
println!("{}", s);
};// 可变借用 -> FnMut
f2();
let s = String::from("closure test value");
let f3 = move || println!("{}", s); // move语句使用相当于把s的所有权移到的闭包内部,闭包外部不能再使用该值 -> FnOnce
f3();
}
闭包底层实现机制。
Fn 不可变引用
FnMut 可变引用
FnOnce (move)
Fn 继承了 FnMut,FnMut 继承了 FnOnce。
宏
一组相关功能的集合称谓。
macro_rules! 构造的声明宏(declarative macro) 以及3中过程宏(procedural macro):
- 用于结构体或枚举的自定义 #[derive] 宏,可以指定随 derive 属性自动添加的代码
- 用于为任意条目添加自定义属性的属性宏
- 看起来类似于函数的函数宏,可以接收并处理一段标记序列
宏是一种用于编写其他代码的代码编写方式,元编程范式。相当于自定义注解?
derive属性是一种宏,自动生成各种 trait 的实现。
宏小册:https://zjp-cn.github.io/tlborm/introduction.html

macro_rules! 声明宏
macro_rules! my_macro {
($($arg: expr), *) => {
// 宏的实现逻辑
println!("Hello, {}", $($arg), *);
}
}
fn main() {
my_macro!("World!");
}
属性宏
允许创建新的属性,而不是为 derive 属性生成代码。
derive 只能被用于结构体和枚举,而属性则可以同时被用于其他条目,比如函数等。
函数宏
实现 kafka 的工具包,发布到 crate.io
https://crates.io/crates/simple-kafka