volatile的应用
volatile是轻量级的synchronized,在并发编程中2个作用:
- 保证了共享变量的可见性
- 禁止指令重排序
可见性的意思是当一个线程修改了一个共享变量时,另一个线程能读到修改的这个值。
volatile的定义与实现
定义如下:
Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排它锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁要更加方便。如果一个字段被声明为volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
有volatile变量修饰的共享变量进行写操作的时候会多出汇编代码,lock。
lock前缀的指令在多核处理器下引发了两件事情:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
原理:
缓存一致性协议 MESI
总线嗅探
禁止指令重排序
https://tech.meituan.com/2014/09/23/java-memory-reordering.html
volatile的使用优化
缓存行是缓存中可以分配的最小存储单位,缓存行64字节。
采用追加字节的方式,使生成的对象占用64字节。
以下有个优化的例子,
A类通过声明7个没有用的long类型变量,加上一个有用的long类型变量x,总共8个long类型变量,共64字节,或者是14个引用类型,引用类型占4字节,加一个long类型变量x,也是64字节。
然后启动两个线程,每个线程对x累加10000000次,x被声明为volatile,每次修改都会对其他线程可见,
把追加的字节删除之后在测试,用时差异比较明显。
追加字节后测试时间大概60几毫秒,
不追加字节测试时间大概200多毫秒。
展开查看
public class CacheLineTest {
static class A{
/**
* 采用追加字节的方式,生成对象A占用64字节,正好是缓存行的容量
* 一个long类型8字节。
* private long a1,a2,a3,a4,a5,a6,a7;
* 一个引用类型4字节。
* private Object a1,a2,a3,a4,a5,a6,a7,a8,a9,aa,ab,ac,ad,ae;
*/
private long a1,a2,a3,a4,a5,a6,a7;
private volatile long x = 0;
public long getX() {
return x;
}
public void setX(long x) {
this.x = x;
}
}
public static long test() throws InterruptedException {
A a1 = new A();
A a2 = new A();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000000; i++) {
a1.setX(i);
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000000; i++) {
a2.setX(i);
}
}
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
long end = System.currentTimeMillis();
long diff = end - start;
System.out.println("花费时间: " + diff);
return diff;
}
public static void main(String[] args) throws InterruptedException {
test();
}
}
synchronized的实现原理与应用
Java中的每一个对象都可以被作为锁。具体表现为以下3种形式:
- 对于普通同步方法,锁是当前实例对象
- 对于静态同步方法,锁是当前类的Class对象
- 对于同步方法块,锁是synchronized括号里配置的对象。
代码块同步是使用monitorenter和monitorexit指令实现的。
monitorenter是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处。任何对象都有一个monitor与之关联,当一个monitor被持有后,它将处于锁定状态。
Java对象头
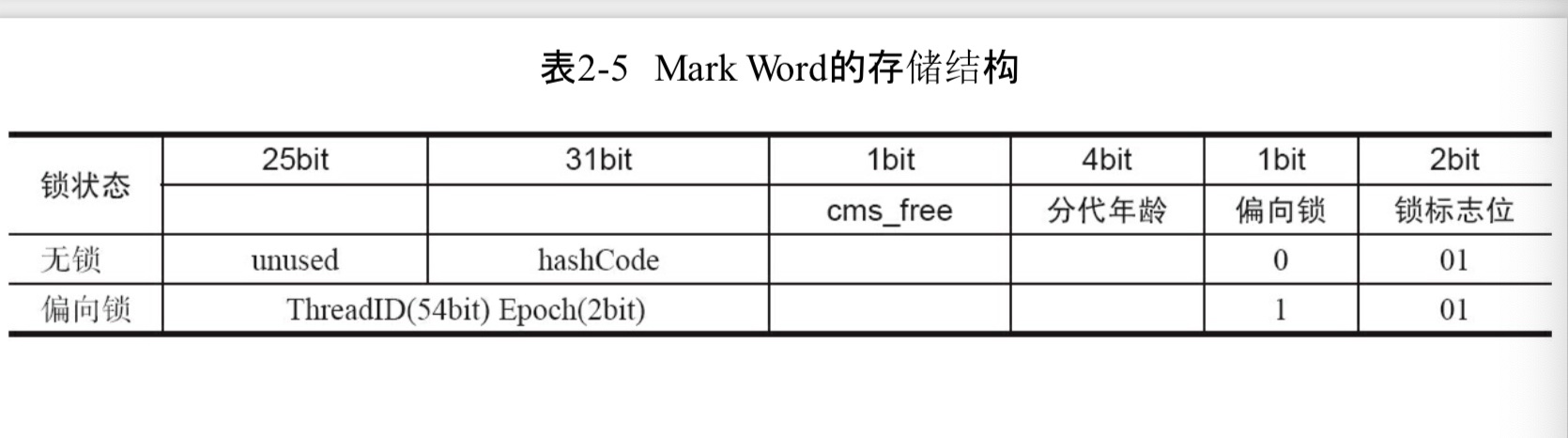
synchronized用的锁是存在Java对象头里的。
Java对象头里的Mark Word里默认存储对象的 HashCode、分代年龄和锁标记位。
64位虚拟机下,Mark Word是64bit大小,其存储结构为:
锁升级与对比
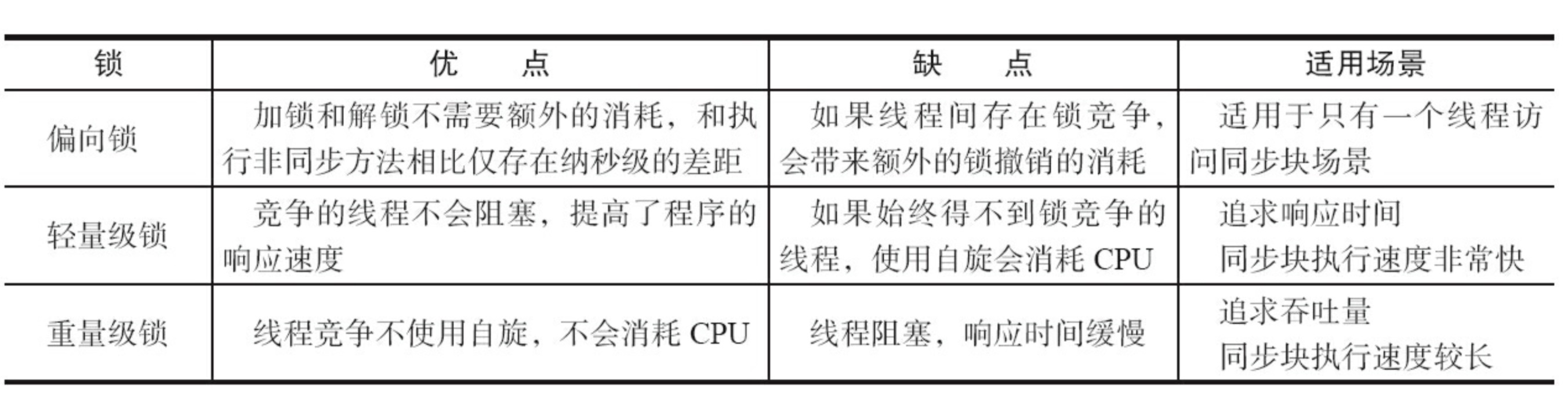
Java SE 1.6 为了减少获得锁和释放锁带来的性能消耗,引入了 “偏向锁” 和 “轻量级锁”。
锁一共有4中状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态随着竞争情况逐渐升级。
锁可以升级但不能降级。目的是为了提高获得锁和释放锁的效率。
偏向锁
Java虚拟机的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一个线程多次获得,为了让这种线程获得锁的代价更低而引入了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储偏向的线程ID,以后该线程在进入和退出同步块时不需要进行加锁和解锁,只需要简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。
偏向锁的撤销
当出现竞争的情况,偏向锁会撤销,并升级为轻量级锁。
偏向锁的撤销需要等待全局安全点(safe point,通常会STW),会首先暂停拥有 偏向锁的线程,然后检查持有偏向锁的线程是否活着,如果线程不处于活动状态,则将对象头设置成无锁状态;如果线程仍然活着,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录,占中的锁记录和对象头的Mark Word要么重新偏向于其他线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。
偏向锁加锁就是将锁的对象头中的线程ID指向自己,使这个锁偏向于自己。
偏向锁的撤销就是将锁对象的对象头中的线程ID设置为空。
轻量级锁
加锁
线程在执行同步块之前,JVM会现在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针,如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
解锁
轻量级解锁时,会使用原子的CAS操作将当前线程的栈帧中的对象头替换回到锁对象的对象头,如果成功,则表示没有竞争发生,如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
自旋会消耗CPU,所以一旦锁升级为重量级锁就不会再恢复到轻量级锁状态。
锁的优点与缺点
原子操作的实现原理
总线锁
所谓总线锁就是使用处理器提供的一个 LOCK# 信号,当一个处理器在总线上输出此信号时,其他处理器的请求将被阻塞住,该处理器可以独占共享内存。
总线锁开销比较大。
缓存锁
缓存一致性协议,MESI。
Java如何实现原子操作
自旋CAS
JVM中的CAS操作利用了处理器提供的CMPXCHG指令实现的。
CAS操作带来的问题:
-
ABA问题
当一个值A,变成B,又变为A,这时候使用CAS进行检查时会发现它的值没有发生变化,但实际上是发生变化的。
ABA问题的解决思路就是使用版本号或者时间戳。
-
循环时间长开销大
-
只能保证一个共享变量的原子操作
锁机制
偏向锁、轻量级锁和互斥锁。
除了偏向锁,JVM实现锁的方式都用了自旋CAS。

